Shallow Semantic Parser for Proceedings titles
Abstract
In the current digital era, almost all of the research findings are communicated and exchanged through different digital means such as scholarly articles. 1. The publishing paradigm of such articles involve scholarly events or journals. In the context of scientific events like symposia, conferences and other meetings the results are published as proceedings of these events. Generally, the title of proceedings composed from a limited subset of the English terms to describe the scope of the events. Therefore, the title of proceedings facilitates metadata extraction by a specialized semantic parser in a computer useable form. This paper presents a semantic parser to extract conference metadata from English titles of proceedings of scientific events. The parser we present is designed and tested based on some 100,000 proceedings titles extracted from three different sources:
- WikiData instances of scholarly articles
- dblp records
- CEUR-WS Volumes.
To improve the flexibility and simplicity of the parser, a combined parser / dictionary based approach was applied. The implementation is done in a test-driven way based on the empirical findings and is made as an open sourced project available at https://github.com/WolfgangFahl/ProceedingsTitleParser.
Keywords
Bibliometrics, Natural Language Processing (NLP), Named-entity recognition (NER), Scholarly Communication, Information Retrieval, Semantic Parsing
Introduction
Conferences are considered as one of the core mediums of scholarly communication in many of the research disciplines. Since the career of researchers heavily depend on multiple factors related to publishing and exchanging their research results, conferences play an important role. Therefore, reliable metadata related to conferences is useful for many usecase scenarios e.g., finding conferences that provide relevant information to support a scholar's research, and identifying venues for publishing research results. This research is related to the ConfIDent project which has a prerequisite of metadata acquisition for conferences from different sources. One of the possible sources if the title of conference proceedings and similar events. As outlined in "Limitations of data sources" below the current availability of metadata on conferences as linked open data sets is limited in the data sources analyzed in this paper.
We have considered the following sources of proceedings titles:
- scholarly articles in Wikidata
- papers from the dblp dataset
- proceeding title references from pdf extraction of http://ceur-ws.org/
| Source | Number of articles scanned | Proceedings titles found | comment |
|---|---|---|---|
| Wikidata | ~35.700.000? | 16.000 | |
| dblp dataset | 10.254.604 | 14208 | |
| CEUR-WS | 48975 | 67606 | pdf-extraction artefacts included |
Usecases
Lookup of events by reference
As a scholar when i find a reference like 'In: proceedings of .... " i want to search for the conference referenced by cut&paste of the proceedings title of the conference into a search engine. The engine should find the presumably existing and unique event. It then should get all the relevant details of the event and present them". Especially i am interested in the quality and trustworthyness of the data (the confidence the system has in the results).
Scenario
The following scenario would be an acceptance criterion for the fullfilling the scholar's needs in this usecase:
Situation
During an internet search on software engineering topics a scholar finds the text:
With a reference:
[Allo96] I. Alloui and F. Oquendo. “PEACE4-: a multi-agent system for computer- supported cooperative work in Software Process Centered Environments.” In Proceedings of 8th International Conference on Software Engineering and Knowledge Engineering (SEKE’96), Nevada, June 1996.
Action
Now the scholar would like to learn more about the SEKE'96 conference. Given his past bad experiences with searching just for the acronym "SEKE'96" he hopes that more information is better and uses cut&paste to search for
Proceedings of 8th International Conference on Software Engineering and Knowledge Engineering (SEKE’96), Nevada, June 1996
E.g at DBLP. See https://github.com/WolfgangFahl/ProceedingsTitleParser/issues/25
This approach leads to: https://user-images.githubusercontent.com/1336221/87436704-aedf1d00-c5ed-11ea-898f-bb627c83af12.png
{kind=link}
with the frustrating result "no matches".
Expected Result
<dblp>
<proceedings key="conf/seke/1996" mdate="2014-12-04">
<title>
The 8th International Conference on Software Engineering and Knowledge Engineering, SEKE '96, Lake Tahoe, Nevada, USA, June 10-12, 1996
</title>
<booktitle>SEKE</booktitle>
<publisher>Knowledge Systems Institute</publisher>
<year>1996</year>
<isbn>0-9641699-3-2</isbn>
<url>db/conf/seke/seke1996.html</url>
</proceedings>
</dblp>
Limitations of data sources
WikiData
As of 2020-06 only 93 entities of type Q74258130 scientific conference Series are available in WikiData.
Example WikiData SPAQRL Query: Conference Series
# WF 2020-06-07
SELECT ?item ?itemLabel
WHERE
{
# scientific conference series (Q47258130)
?item wdt:P31 wd:Q47258130.
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
}
Wikidata Proceedings instances
As of 2020-06 some 1200 proceedings in Wikidata are instances of
and can be e.g. directly queried with: wikidata vizquery for proceedings
Proceedings titles as a source for conference metadata
A proceedings title like “Computer-assisted modeling of receptor-ligand interaction. Theoretical aspects and applications to drug design. Proceedings of the 1988 OHOLO Conference. Eilat, Israel, April 24-28, 1988” (see http://www.wikidata.org/entity/Q69349965) contains metadata such as the name, location and date of the event. Unfortunately this metadata information is currently mostly not available as an open data set linked to the conference proceedings.
By applying shallow semantic parsing to the proceedings titles, we intend to automate the extraction of the metadata and subsequently make it available as linked open data. E.g. we'd like to link the data on proceedings of a conference with the data on the conference itself. For conferences series we'd like to link the data of the conference with the corresponding conference.
Such linking is already available on a few platforms like dblp but quite a few cross platform links are still missing on the platforms considered in this paper.
Wikidata as a source of proceeding titles
As of 2020-06, some 35.7 million scholary article entities are available via Wikidata. We have used the https://tools.wmflabs.org/wdumps/ tool to create an RDF dump of the data of these entities https://tools.wmflabs.org/wdumps/dump/420.
In the next step, we filtered English proceeding titles by using the Unix command-line tool "grep" with the search expression "proceedings of". The resulting text file contained one subject-predicate-object triple per proceedings volume, e.g., for the above example:
<http://www.wikidata.org/entity/Q69349965> <http://www.w3.org/2000/01/rdf-schema#label> "Computer-assisted modeling of receptor-ligand interaction. Theoretical aspects and applications to drug design. Proceedings of the 1988 OHOLO Conference. Eilat, Israel, April 24-28, 1988"@en .
In total, we obtained a sample of 16,000 proceedings titles this way.
The analysis of the proceeding titles was facilitated by using a Python script with a simple first parsing approach. The first parsing approach separated each title into tokens by using whitespace as a delimiter. Then a dictionary in human readable "yaml" format was created that contained lookup tables for common words which were found in the proceeding titles. The dictionary was grouped into 14 dictionary elements.
Dictionary elements
This table shows the dictionary elements that already cover 65% of the most used words in proceedings titles. The assumption is that the 35% "long tail" will mostly have acronym and field information while adding more countries, city, enum and the like will not have much of an effect any more on the coverage. Please that the differenciation between upper and lowercase is on purpose.
| type | count | most common examples: count |
|---|---|---|
| city | 52 | York: 426, London: 375, Washington: 274, Paris: 202, Tokyo: 198 |
| country | 26 | USA: 1031, Italy: 651, Japan: 525, Germany: 495, France: 465 |
| delimiter | 4 | -: 198, &: 75, :: 38 |
| enum | 320 | 2nd: 375, 3rd: 315, 4th: 299, First: 277, 5th: 275 |
| event | 20 | Symposium: 2316, Conference: 2030, symposium: 1834, meeting: 1618, Meeting: 1575 |
| field | 84 | Health: 591, Clinical: 416, Medical: 380, Cancer: 367, Medicine: 336 |
| frequency | 4 | Annual: 969, annual: 735, Biennial: 45, Triennial: 7 |
| month | 12 | September: 1519, June: 1307, October: 1300, May: 1099, April: 988 |
| organization | 16 | Society: 3114, Association: 1054, Societies: 493, University: 310, Group: 272 |
| province | 19 | California: 398, Maryland: 246, Florida: 172, Massachusetts: 132, Pennsylvania: 124 |
| publish | 6 | Proceedings: 15965, Abstracts: 775, Research: 769, research: 250, Advances: 239 |
| scope | 31 | International: 3632, international: 606, American: 598, European: 588, British: 529 |
| syntax | 23 | of: 25933, the: 17700, and: 7257, on: 4735, in: 3717 |
| year | 70 | 1988: 434, 1997: 411, 1989: 407, 1986: 404, 1995: 392 |
Example lookup of tokens

The dateRange syntax element was added later when we switched to an improved parser and is not based on a dictionary.
Event Series and the enum element
Quite a few events are part of a series of events. E.g.
Catecholamines in the cardiovascular system. Proceedings of the 23rd Symposium on Catecholamines in the Cardiovascular System. Tokyo, Japan. November 30, 2002
http://www.wikidata.org/entity/Q73578487 is the title of the 23rd event in a series. The wikidata sample has two entries of proceedings for the corresponding series which can be found with the unix "grep" tool like this:
grep "Symposium on Catecholamines in the Cardiovascular System" proceedings.txt | grep "@en"
<http://www.wikidata.org/entity/Q74122319> <http://www.w3.org/2000/01/rdf-schema#label> "Proceedings of the 22nd Symposium on Catecholamines in the Cardiovascular System. Tokyo, Japan, October 28, 2000"@en .
<http://www.wikidata.org/entity/Q73578487> <http://www.w3.org/2000/01/rdf-schema#label> "Catecholamines in the cardiovascular system. Proceedings of the 23rd Symposium on Catecholamines in the Cardiovascular System. Tokyo, Japan. November 30, 2002"@en .
Since the enumerating (ordinal) of events can be specified in a few different ways e.g.
- Arabic: 1,2,3, ..., 23
- Roman: I, II, III, ..., XXIII
- Ordinal words: First, Second, Third, ..., Twenty-third
it is necessary to find the numeric value of the enumeration. To simplify this the dictionary contains the "value" for each enumerarion e.g.:
grep -B 2 "value: 23" dictionary.yaml
'23.':
type: enum
value: 23
--
23rd:
type: enum
value: 23
--
Twenty-third:
type: enum
value: 23
--
XXIII.:
type: enum
value: 23
Feasibility check of dictionary use
With a python unit test it was checked how many proceedings title in the 16.000 Wikidata samples could be successfully parsed using the dictionary. The most often used words were entered into the dictionary and the type of the word determined. In total 261,899 tokens where parsed of which 170,604 (65%) could be looked up in a dictionary with 694 entries.
Using a Grammar based parser
Then next step in improving the parser is applying a Proceedings titles specific grammar. The list of dictionary elements found with the with the dictionary approach has shown that it might be feasible to parse the proceedings titles by assuming that each dictionary element can be described as a grammar element. Also there are elements like daterange which were found but not handled by the dictionary approach yet. E.g. to analyze time metadata like "25-28 August, 2010" the three grammar elements
- daterange
- month
- year
with the expected parse tree to be:
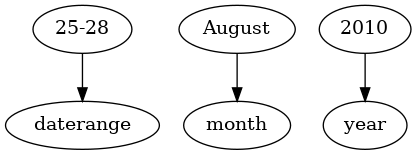
would be used. In this step we can now add extra flexibility. We now have the option to derive the grammar element from a dictionary element or specify a rule based approach. E.g. for the dictionary element "year" it seems awkward to have a dictionary of all years that might be valid. It is much simpler to specify a grammar rule that specifies a year to be a 4 digit number. For the month both options seem to be equally valid - there are only 12 different options in theory. The dictionary approach has the advantage that it would be easier to e.g. internationalize the paser because the parser itself could be fixed but use different dictionaries for different languages. For the daterange the grammar approach is definitly to be preferred because otherwise the dictionary would have to have a entries for a few hundred valid combination of dates that do not really add value to the dictionary.
We used the pyparsing-library for the grammar approach. Pyparsing describes the grammar in a human readable way right in the source code. Unfortunately there seems to be no tool to convert the source code to BNF form so the source code is shown verbatim below:
proc=Keyword("Proceedings") | Keyword("proceedings")
descWord=~proc + Word(alphas+nums+"™æéç)>/'&—‐") # watch the utf-8 dash!
initials="("+OneOrMore(Word(alphas)+".")+")"
desc=Optional("[")+OneOrMore(descWord|initials)+oneOf(". ? : ( , ; -")
enumGroup=dictionary.getGroup("enum")
scopeGroup=dictionary.getGroup("scope")
eventGroup=dictionary.getGroup("event")
freqGroup=dictionary.getGroup("frequency")
yearGroup=dictionary.getGroup("year")
cityGroup=dictionary.getGroup("city")
provinceGroup=dictionary.getGroup("province")
countryGroup=dictionary.getGroup("country")
eventClause=dictionary.getClause("event")
monthGroup=dictionary.getGroup("month")
extractGroup=dictionary.getGroup("extract")
dateRangeGroup=Group(Optional(Word(nums)+Optional("-"+Word(nums))))("daterange")
prefixGroup=Group(ZeroOrMore(~oneOf(eventClause)+Word(alphas+nums)))("prefix")
topicGroup=Group(ZeroOrMore(~oneOf("held on")+Word(alphas+nums+"-")))("topic")
part="Part"+oneOf("A B C 1 2 3 4 I II III IV")+"."
whereAndWhen=Optional(oneOf([".",",","held on"])+dateRangeGroup+monthGroup+dateRangeGroup \
+Optional(oneOf(","))+yearGroup \
+Optional(oneOf(","))+cityGroup \
+Optional(oneOf(","))+provinceGroup \
+Optional(oneOf(","))+countryGroup \
+Group(Optional(Word(alphas)))("location"))
self.grammar=Group(ZeroOrMore(desc))("description") \
+Optional(part) \
+Optional(oneOf("[ Conference Scientific")) \
+extractGroup+Optional(oneOf("the The"))+Optional("Official") \
+proc+"of"+Optional(oneOf("the a an")) \
+yearGroup \
+enumGroup \
+freqGroup \
+scopeGroup \
+prefixGroup \
+Optional(oneOf("Scientific Consensus"))+eventGroup \
+Optional(oneOf("on of in :")) \
+topicGroup \
+Optional(oneOf("] )")) \
+whereAndWhen
dictionary.getGroup is the function which converts a list of dictionary elements with a given type to a list of valid grammar tokens allowing to use a dictionary type directly as a grammar element. This makes the grammar much more readable and flexible than specifying the list of possible token elements in the grammar itself.
match results
For the three different test sets of proceedings titles the parsers matching capability is over 97% in all cases. In a test driven development cycle for each special case found another test example was added. Special cases found where e.g. the use of UTF-8 chars like "‐" which looks like a dash but isn't or accents like "æéç" which are not in the default character set of the pyparsing library.
The test examples for the grammar above where are shown below in the corresponding python unit-test:
def testExamples(self):
''' test specific examples for parsing success '''
titlelines=[
"Computer-assisted modeling of receptor-ligand interaction. Theoretical aspects and applications to drug design. Proceedings of the 1988 OHOLO Conference. Eilat, Israel, April 24-28, 1988",
"Advances in chronic kidney disease 2009. Proceedings of the 11th International Conference on Dialysis. January 28-30, 2009. Las Vegas, Nevada, USA",
"Nutrition in Clinical Management of HIV-Infected Adolescents (>14 y old) and Adults including Pregnant and Lactating Women: What Do We Know, What Can We Do, and Where Do We Go from Here? Proceedings of a conference held in Washington, DC, July 26-28",
"Abstracts of the Official Proceedings of the 11th Annual Meeting of the American Society of Breast Surgeons. April 28-May 2, 2010. Las Vegas, Nevada, USA",
"Old and New Dopamine Agonists in Parkinson's Disease: a Reappraisal. Proceedings of the LIMPE Seminar, 26-28 February, Pisa, Italy, 2009",
"The Proceedings of the 97th Tohoku Regional Meeting of the Japanese Society of Neurology",
"Subchondral Pathology: Proceedings of the International Consensus Meeting on Cartilage Repair of the Ankle",
"Scientific Proceedings of the Twenty-seventh Annual Meeting of the American Association of Pathologists and Bacteriologists",
"Bulletins et Mémoires de la Société Française d'Ophtalmologie: Proceedings of 1980 Congress",
"British Pædiatric Association: Proceedings of the First Annual General Meeting",
"Advances in Medical Computing (Proceedings of the 3rd International Symposium on Computers in Medicine)",
"Red Drum Aquaculture, Proceedings of a Symposium on the Culture of Red Drum and Other Warm Water Fishes",
"A summary of the Proceedings of the Twelfth International Symposium on the Neurobiology and Neuroendocrinology of Aging, Bregenz, Austria July 27-August 1, 2014.",
"[Update on vaccine research. Proceedings of the 15th annual conference on vaccine research organized by the National Foundation for Infectious Diseases].",
"Very broad Markush claims; a solution or a problem? Proceedings of a round-table discussion held on August 29, 1990.",
"Abstracts From the Proceedings of the 2015 Annual Meeting of the Clerkship Directors of Internal Medicine (CDIM).",
"Christo Deltshev & Pavel Stoev (eds) (2006): European Arachnology 2005, Acta zoologica bulgaria, Suppl. No. 1; Proceedings of the 22nd European Colloquium of Arachnology, Blagoevgrad, Bulgaria, 1-6 August 2005",
"(L.) Bricault and (M.J.) Versluys Eds Power, Politics, and the Cults of Isis: Proceedings of the Vth International Conference of Isis Studies (Religions in the Graeco-Roman World 180). Leiden: Brill, 2014. Pp. xvii + 364. €139/$180. 9789004277182",
"Kunaitupii: Coming Together on Native Sacred Sites—Their Sacredness, Conservation and Interpretation. Brian O. K. Reeves and Margaret A. Kennedy, editors. Proceedings of the First Joint Meeting of the Archaeological Society of Alberta and the Monta",
"Jan Apel and Kjel Knutsson: Skilled Production and Social Reproduction. Aspects of Traditional Stone‐Tool Technologies. Proceedings of a Symposium in Uppsala, August 20–24, 2003",
"Developing ambient intelligence - proceedings of the first international conference on ambient intelligence developments."
#"Sea Lice 2003 - Proceedings of the sixth international conference on sea lice biology and control"
]
parser=self.getParser()
tc=Counter()
for line in titlelines:
self.tryParse(line, parser, tc)
self.assertEqual(tc["success"],len(titlelines))
Using a Graph of Terms
Building on the dictionary approach the next step was to create a graph of the terms found while parsing. Each node in the graph consist of a term found in a proceedings title. A term can consist of one or multiple words and is either a syntactic element like "of the" or a term containing relevant typed meta-data information like "Symposium" of type "event. Terms may consist of multiple words so "San Francisco" is a term consisting of two words of type "city".
Example Graphs of Terms
Input taken from dblp xml
<title>Proceedings of the 27th International Symposium on Graph Drawing and Network Visualization (GD 2019).</title>
<title>Proceedings of the 25th International Symposium on Graph Drawing and Network Visualization (GD 2017).</title>
<title>Proceedings of the 24th International Symposium on Graph Drawing and Network Visualization (GD 2016).</title>
<title>Proceedings of the 26th International Symposium on Graph Drawing and Network Visualization (GD 2018).</title>
Graphical representation of the graph of terms

Input taken from WikiData
grep "International Symposium on Avian Influenza" proceedings.txt
<http://www.wikidata.org/entity/Q79344682> <http://www.w3.org/2000/01/rdf-schema#label> "Proceedings of the 5th International Symposium on Avian Influenza. Athens, Georgia, USA. April 14-17, 2002"@en .
<http://www.wikidata.org/entity/Q86564245> <http://www.w3.org/2000/01/rdf-schema#label> "Proceedings of the 8th International Symposium on Avian Influenza, April 1-4, 2012, London, Great Britain"@en .
<http://www.wikidata.org/entity/Q80467391> <http://www.w3.org/2000/01/rdf-schema#label> "Proceedings of the Sixth International Symposium on Avian Influenza. April 3-6, 2006. Cambridge, United Kingdom"@en .
<http://www.wikidata.org/entity/Q84580794> <http://www.w3.org/2000/01/rdf-schema#label> "Proceedings of the Seventh International Symposium on Avian Influenza. April 5-8, 2009. Atlanta. Georgia. USA"@en
Please note the slight differences in wording, order and usage of syntactical elements. The 5th Symposium as the date at the end of it's title, while the others have the location at the end. The 5th and 8th use an arabic ordinal but not the 7th instead "Seventh" is used for the enumeration. Another difference is: "Great Britain" (country) - "London" (city) for the location but "United Kindom" as a country for the city "Cambridge" which is in fact in the same country. For the location "Georgia, USA," is used in the title of the 5th Symposium separating city and province by a comma but "Atlanta. Georgia." using a dot as a separator for the title of the 7th Symposium held in a location close by.
For a human these slight differences might be no big issue - for a systematic computerized approach it makes more sense to standardize the format of the metadata retrieved to ease the access to and analysis of such data.
Histogram analysis
The word count distribution for the proceeding titles of the four sources first looked like this:




The outliers in these distributions have been further analyzed assuming artifacts might be the reason.
- For ceur-ws we found that empty newlines had been created during the filtering from html to text.
- After improving the filter to retrieve more titles the ceur-ws histogramm didn't have the outlier at word count "1" any more - but the distribution looked suspicously wide:

reanalysis
SQL-Query
select source,title from event
where title like '%Proceedings of%'
and source in ('wikidata')
Diagrams




Discussion and Conclusion
Notes
Related Work
- Parsing of Tweets see http://ceur-ws.org/Vol-1691/paper_14.pdf
grobid
Example
Tested on https://grobid.bitplan.com Service to call: Process Citation
Input:
Proceedings of the International Workshop on Algorithms & Theories for the Analysis of Event Data 2020 (ATAED 2020),virtual workshop, June 24, 2020
Output:
<biblStruct >
<monogr>
<title level="m">Proceedings of the International Workshop on Algorithms & Theories for the Analysis of Event Data 2020 (ATAED 2020),virtual workshop</title>
<meeting>the International Workshop on Algorithms & Theories for the Analysis of Event Data 2020 (ATAED 2020),virtual workshop</meeting>
<imprint>
<date type="published" when="2020-06-24" />
</imprint>
</monogr>
</biblStruct>
Falcon
Example
Input:
Proceedings of the 27th International Symposium on Graph Drawing and Network Visualization (GD 2019)
Output:
{
"entities": [
[
"http://dbpedia.org/resource/International_Symposium_on_Graph_Drawing",
"27th International Symposium on Graph Drawing"
],
[
"http://dbpedia.org/resource/Sum_activity_of_peripheral_deiodinases",
"(GD"
],
[
"http://dbpedia.org/resource/Visualization",
"Network Visualization 2019)"
]
],
"relations": [
[
"http://dbpedia.org/ontology/review",
"proceedings"
]
]
}
Libraries Used
- https://github.com/pyparsing/pyparsing
- https://pypi.org/project/pywikibot/
- https://pypi.org/project/py-3rdparty-mediawiki/
- https://pypi.org/project/Flask/
- https://pypi.org/project/flask_accept/
- https://pypi.org/project/PyYAML/
- https://pypi.org/project/num2words/
- https://pypi.org/project/beautifulsoup4
- ...
Appendix
Scholarly Search engine Trials
CiteSeer
ATAED 2020
- https://citeseerx.ist.psu.edu/search?q=Proceedings+of+the+International+Workshop+on+Algorithms+%26+Theories+for+the+Analysis+of+Event+Data+2020+%28ATAED+2020%29%2Cvirtual+workshop%2C+June+24%2C+2020&submit.x=0&submit.y=0&sort=rlv&t=doc gives 54.74 results as of 2020-07-03.

RefSeek
BIR 2019



DBLP
For DBLP search test see https://github.com/WolfgangFahl/ProceedingsTitleParser/issues/25
WOS

References
- ^ Mohamad Yaser Jaradeh, et. al. (2019) "Open Research Knowledge Graph: Next Generation Infrastructure for Semantic Scholarly Knowledge" K-CAP ’19, November 19–21, 2019, Marina Del Rey, CA, USA . doi: 10.1145/3360901.3364435
- ^ Patrice Lopez. (2009) "GROBID: Combining Automatic Bibliographic Data Recognition and Term Extraction for Scholarship Publications" ECDL 2009: Research and Advanced Technology for Digital Libraries pp 473-474 . doi: 10.1007/978-3-642-04346-8_62url: https://core.ac.uk/download/pdf/38300913.pdfat: ECDL 2009
- ^ Ahmad Sakor, Isaiah Onando Mulang, Kuldeep Singh, Saeedeh Shekarpour, Maria-Esther Vidal, Jens Lehmann, Sören Auer. (2019) "Old is Gold: Linguistic Driven Approach for Entity and Relation Linking of Short Text" Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL 2019) . doi: 10.18653/v1/N19-1243at: NAACL 2019